|
Произойдет
случайно...
Что остается?
Тайна.
Мерайли
| |
| |
В этом слове истинное таинство. Притаилась внутри: вроде, простая, — а не перелистать; то ли взлетает, то ли перестает; и кажется: вот-вот растает, — но нет, держит на расстоянии, лишь краешком прорастая из тайника... Прикоснемся на миг к высокой поэзии, — повздыхаем, повосхищаемся — и вернемся к обыкновенным, понятным и простым словам.
Есть фонологический факт: тайный и таинственный — слова разные; а различаются они качеством соединения звуков [а] и [и]. Когда мы в школе делим все на слоги, черточки расставляем примерно так: тай-ный — та-ин-ствен-ный. Как по волшебству: то они вместе — то по отдельности. Но высшая мистика начинается, когда мы не полагаемся на школьную премудрость, а начинаем читать стихи — и вслушиваться в живое звучание. Оказывается, никакого расползания по разным слогам и нет вовсе: сочетание [аи] в слове таинственный читается слитно, как один звук, — и поэты начали играть ритмами сразу же после того, как силлабо-тоническая система стала официально признанной нормой русского стихосложения:
Душа трудилась неустанно —
И узнала, поняла она,
Что таится в бездне океана,
В чем звезд и сердца глубина...
| |
Сначала вольности стыдливо именовались "видоизменением" (ипостаса, стяжение, анакруза, кретик...); кивали на народные традиции (дольник); потом тов. Маяковский приучил публику к акцентному стиху, с его бесконечно разнообразными ритмическими узорами, — и в наши дни отсутствие чего-то эдакого расценивается как бездарный примитив.
Сухой остаток: судьбоносная встреча гласных [а] и [и] в тексте может кончаться очень по-разному. Иногда звуки сухо поздороваются — и каждый остается сам по себе; в другой раз гласная [а] притягивает к себе последующее [и], отнимает у него самостоятельность, превращает в "недогласную" [й], — но бывает и наоборот: редуцированное [а] (превращенное в [ǝ]) полностью отдается во власть последующего [и]. По-иностранному это называется "дифтонг"; считается, что в русском языке такого нет, а если и есть — то серьезной науке параллельно.
Правда, иностранные дифтонги тоже не так просты. В тамошней школе дифтонг (и даже трифтонг с эризацией!) идет за один слог — и это соответствует разговорной практике. Но в песнях дифтонги могут-таки разъять на части, когда по музыке так удобнее (если не говорить, конечно, о несокрушимом китайском слоге, единстве звучания и семантики). А присмотревшись к итальянским поэтам, находим еще один тип слияния: две или три гласные подряд (с окружающими согласными) считаются одним слогом — но при этом никто на себя одеяло не перетягивает, каждая гласная сохраняет свое лицо. Возвращаясь в Россию, обнаруживаем подобное и здесь: например, в словах наименьший и наибольший.
Понятно, что есть и другие примеры. Гласная [у] тоже умеет редуцировать соседей — или самозабвенно прилепиться к ним. Остальные, понятно, не отстают. Начинают закрадываются сомнения: так ли все однозначно с набором гласных русского языка? — нет ли и здесь тайны?
Дискурсивный кульбит — и мы уже в теории музыки... Нам указывают на пианино и вводят в курс: есть двенадцать нот, и все музыкальные звуки (в отличие от шумов) поделены на октавы, в каждой ровно двенадцать ступеней, отстоящих друг от друга на одно и то же музыкальное расстояние (интервал); а что различается на октаву — мы отождествляем. Любую мелодию можно "транспонировать" — перенести вверх или вниз на любое число элементарных ступенек, — и от этого мелодия не перестанет быть собой. Точно так же, аккорд заданной структуры сохраняет качественное своеобразие независимо от того, что мы сделаем его первой нотой. Тов. Бах (Иван Севастьянович) нам это очень художественно доказал.
Наивный вопрос: а почему клавиши разного цвета? Ответ: по историческим причинам. Раньше считали, что объединить вместе можно только семь нот — и если начинать с разных мест, получаются разные тональности, по-разному устроенные. Чтобы соединять в оркестре музыкальные инструменты с разной настройкой, пришлось ввести дополнительные ноты, и приделать к роялю черные клавиши. Но на самом деле все ноты равноправны — и на других инструментах (например, баян) клавиши одинаковые.
Вопрос еще глупее: почему уважаемый тов. Бах написал 24 разных пьесы для иллюстрации возможности сочинения музыки в любой из тональностей? Зачем этот мартышкин труд? Достаточно попросить музыкантов исполнить одну пьесу, начиная от разных нот. Ну, или две — мажорную и минорную. Кстати, а чем одно от другого отличается?
Музыкальный педагог хватается за голову и музыкально матерится — после чего заявляет, что нам не место в музыке, раз мы не понимаем общеизвестных вещей... А если мы родной язык воспринимаем как сплошную загадку — так что же, уже и говорить запрещено?
Если покопаться в истории музыки, с удивлением обнаруживаем, что наши дурацкие вопросы веками кошмарят самых крутых музыкантов, и удовлетворительного ответа нет до сих пор. Почем именно двенадцать нот — и откуда берутся лады, тональности, аккорды? Как это подружить с народной (этнической) музыкой, где роялей отродясь не водится? Можно ли придумать другие наборы нот (звукоряды), чтобы так же красиво, и на слух легло? Как строение музыки связано со строением звукоряда?
Совсем недавно (на фоне музыкальных тысячелетий) в конце этого бездорожья что-то забрезжило. Усилиями нескольких музыкантов, математиков, физиков и психологов удалось построить (не то, чтобы очень) простую, но почти всеобъемлющую теорию, из которой ныне наблюдаемое железно следует, — и предсказаны художественные особенности нескольких недостаточно изученных звукорядов, дальше которых, по-видимому, дело уже и не пойдет. После этого неожиданно выяснилось, что похожие эффекты наблюдаются и в изобразительных искусствах, — хотя ничего похожего на математическую модель музыкального восприятия там и близко нет. Философские соображения ведут к навязчивой идее: в любой человеческой деятельности универсальные механизмы приводят к возникновению похожим образом устроенных дискретных структур (шкал), с возможностью тонкой подстройки интонаций (вариантов реализации) в пределах фиксированной шкалы. А раз так — почему бы не поискать аналоги музыкальных строев в русской фонологии?
С одной стороны, очень удобно: уже есть набор теоретически обоснованных шкал, и достаточно примерить их к языку, выбрать подходящую (или несколько, для разных речевых ситуаций). Но есть риск вместо добросовестного анализа увлечься собственными находками и притягивать за уши примеры, силой запихивать трепещущую материю в формальный гроб. Конечно, если бы удалось обнаружить сходство деятельности — тогда и математика пришлась бы к месту, и выявлять соответствия намного легче. Но, к сожалению, тут как и с графикой: убедительно подтверждаемого родства речевых явлений и музыки предъявить не могу.
Чтобы хоть как-то откреститься от артефактов, придется все-таки идти не от теории, а от языковой обыденности, усматривать скрытые структуры в фонологии, исходя из нее самой. Только потом, задним числом, допускается сопоставить результат (буде таковой появится) с глобальной математикой: если сойдется — хорошо; если не очень — тем хуже для математики.
Сразу предупреждаю: искать фонологические структуры будем безотносительно к реалиям речепорождения. Фонема как культурное явление не сводится к положению органов артикуляции, спектральным характеристикам сигналов или набору условных рефлексов. Наоборот, мы подстраиваем нашу звучащую и слушающую аппаратуру (без разницы, белковую или электрокомпьютерную) таким образом, чтобы звуки получались достаточно характерные, и воспринималось это как последовательность фонем, а не абстрактный вокализ. Обучать детей говорить и слышать родители начинают еще до физиологического рождения, а после — подключаются всевозможные общественные структуры: от масс-медиа до школы и вузов. Поэтому человеческий мозг (и его компьютерные модели) умеет обслуживать общение. Нужно говорить на иностранном языке — процесс настройки техники начинается заново (хотя и не совсем с нуля, ибо механизмы речи кочуют из одного языка в другой).
Фонология — дело тонкое, и нельзя, вообще говоря, заранее предполагать группировку всевозможных звучаний в сколько-нибудь упорядоченный набор фонем. Если на то пошло, поначалу оно так и кажется: есть хаос точек в каком-то фонологическом пространстве, и группируются они в компактных областях сугубо статистически. В любом языке фонемы — чистая эмпирия. Разделить их на классы и группы можно лишь весьма условно. Традиционные классификации исходят из физики и физиологии — а это как раз не то, чего мы хотим. Отличать одно от другого желательно по культурным признакам, по способу употребления. Очень грубый (и поэтому наглядный) пример: гласные — то, что тянется и создает слог; согласные — все остальное (переходные процессы). Но тогда [м] [н] [л] [р] [с] [ш] запросто могут претендовать на роль гласных! А по большому счету, все вообще согласные можно затянуть и сделать слогообразующими. Чем некоторые языки и пользуются. Несмотря на это, современная культура русскоязычия все же опирается на различие гласных и согласных, и воспитывает именно такое слышание у всех законопослушных членов общества. И наше дело не воевать с мельницами, а понять, почему те или иные шкалы оказываются культурно обусловленными.
Значит, сужаем предметную область: говорить пока будем только о гласных. Возможно, выводы окажутся применимы и к согласным — но с чего-то же надо начать.
Согласно последней описи, в русском языке пять открытых гласных; для определенности, обозначим их [A] [E] [I] [O] [U]. Каждой открытой гласной сопоставляется закрытый аналог, который мы будем обозначать такой же строчной буквой: [a] [e] [i] [o] [u]. Я намеренно не использую русские буквы — чтобы не было ассоциаций с принятой сейчас системой письма, в которой буквы, в зависимости от контекста, могут обозначать очень разные фонемы (или даже их комбинации). Квадратные скобки подчеркивают, что и латинский алфавит имеет к фонологии лишь отдаленное отношение, и даже самые удачные обозначения — не более чем условность. По идее, следовало бы привести энное количество примеров для пояснения обозначений; в расчете на русского читателя, я этот этап опускаю: вспоминаем школьные годы. Замечу только, что закрытое [o] возникает чаще всего при чтении буквы ё после согласных, тогда как гласная [i] больше известна в нейотированном варианте.
Разумеется, в окружении других звуков фонемы в какой-то мере меняют качество; здесь континуум вариаций. Есть диалектные и групповые предпочтения. Однако представление о десяти гласных — факт русской культуры, и никакие теоретические баталии не могут его поколебать минимум сотню лет. Несомненно, современная кириллица оказывает влияние на теоретиков, а нормы письменности испытывают влияние модных теорий. Русская орфография пережила несколько реформ — но тенденция к упрощению и отмене лишних букв тоже не случайна: самосознание догоняет сознание. Всякая реформа закрепляет уже сложившийся порядок вещей: это конец пути, а не его начало. На данный момент мы знаем десять гласных — будем исходить из культурной реальности.
Вдумчивый читатель укажет на притаившуюся в рассуждениях ошибочку: гласных-то в русском языке не десять, а больше! Только изображаются они на письме все теми же десятью буквами. Но звучат очень даже по-своему. Пока мы интересуемся исключительно семантикой, нас устраивает и десятибуквенная нотация. А в фонологии так нельзя: тут надо честно огласить весь список — и только тогда вынюхивать закономерности.
Согласен. И возражаю. Гласных много. И все они разные. Но где грань? Одно плавно перетекает в другое, одни слышат больше, чем другие... Откуда нам знать, что вот это изменение приводит к аллофонии — а с виду такое же, но чуток побольше, качественно меняет фонему? Арбитр у нас все тот же: практика. Если народ по жизни употребляет фонемы как одинаковые — они одинаковые, даже если тренированное ухо лингвиста разводит их по берегам пропасти. Задача фонологии — не изобретать фантастически правильные системы, а наблюдать за языковой неправильностью и догадываться, как трудящиеся массы внутри себя звуки раскладывают. Само собой, народу по мелочам рефлексировать незачем: у них дела поважнее. Никто не скажет нам в открытую, что различается, а что нет. Спроси любого — наверняка ошибется. Не потому, что не понимает, — а просто выразить понятное понятно не всяк научен, и не всякому досуг научиться. Поэтому судить ученый лингвист будет по делам, по факту общения и типовым средствам его развертывания и поддержания.
На этом этапе культурные образования приходится дополнять образованием наблюдателя, и ошибки в интерпретации происходящего никак не исключены. Мало ли, что кому покажется! Тем более, что большой ученый частенько живет и трудится в несколько иных, рафинированных условиях, далеко от повседневной борьбы за кусок хлеба и кров над семьей, — и понять народную душу иной раз просто не в состоянии. Но поскольку я не ученый, и не особенно большой, — попробую все же пополнить коллекцию поводов для размышления.
Всем известно, что в безударном слоге (например, в слове потолок) буква о читается примерно так же, как буква а, и только в некоторых диалектах сохраняется полное звучание [O]. Более того, наряду с оканьем, есть и подчеркнутое произношение слабого [A], в том числе на месте о (аканье): а маманя-та, савсем плаха! С точки зрения науки, речь идет не просто о чередовании гласных, а о появлении особой фонемы, соединяющей черты звуков [O], [A]; в разном окружении она становится больше похожей на какой-то один из этих звуков — но до конца не сводится ни к одному из них. Различие диалектов — в способах трактовки этой новой целостности, которую мы называем кластером и обозначаем как [(A)].
Закономерный вопрос: объединяются ли в кластер закрытые варианты тех же фонем? Не совсем так. Вместо склеивания [o] и [a] мы наблюдаем склеивание [a] и [e] в кластер [(e)]: тряпица, притягательный, клянусь — в нормативной речи звучат примерно как трепица, притегательный или кленусь. В акающих местностях центр тяжести кластера сдвигается — и мы можем слышать звук [(a)] во всей красе. Точно так же, иностранцы пытаются прочесть "как написано" — и попадают впросак, в другой кластер. Но для наших целей ограничимся нормативным произношением.
Еще один кластер соединяет свойства [i] и [e], но звучит ближе к [i], и мы будем обозначать его по тому же принципу, как [(i)]. Именно так читаются неразличимые в безударных слогах буквы и, е: кривой, слепой. Спрашиваем наоборот: есть ли открытый аналог кластера [(i)]? Выясняется: есть! Достаточно сравнить: космонавты — космонавтика, мужика — шарика, стрелы — звери... Однозначная парочка [(I)] — [(i)].
Еще что-нибудь? Ну, если угодно... Пара кластеров [(U)] — [(u)] проглядывается в сопоставлениях вроде: вижу — верю, туда — сюда... Слияние звуков [U], [O] — и [u], [o].
Важный практический вывод: при обсуждении кластеров мы все равно остаемся в рамках стандарта десяти гласных; похоже, это более фундаментальная структура, а кластеры лишь "надстраиваются" над ней. Когда получат "промежуточные" звучание отдельные знаки на письме — тогда возможно говорить об их равноправии. А пока — не пора...
Хорошо, пусть за основу узаконенная десятка. Это приятно: русский язык сближается с европейскими — прежде всего, итальянским. Вопрос на засыпку: существует ли в этом наборе какой-либо естественный порядок? Другими словами, можем мы трактовать различие гласных как исключительно количественное? Или фонемы качественно различны и надо делать их отдельными измерениями фонологического пространства, с количественными градациями внутри каждой по отдельности?
Философский ответ: это зависит. В каких-то отношениях так — в других иначе.
Прекрасно. Допустим так. Тогда как будем расставлять?
Вот тут на помощь приходят кластеры. Если несколько звуком по жизни склеиваются — значит, они стоят на общей для всех шкале где-то рядом! Элементарное сопоставление дает "естественный" порядок:
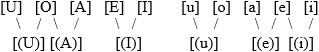
В принципе, располагать можно было бы и в зеркальном отражении: от [I] к [U], и от [i] к [u]. Мой выбор, конечно же, субъективен: мне почему-то кажется, что [U] ниже [I]. Возможно, я заблуждаюсь; но может оказаться, что мое восприятие выражает нечто общее для всех носителей языка, культурно сложившийся стереотип. Можно это проверить экспериментально — а можно оценить логические последствия, и на этом основании судить о верности предпочтений.
Имеющийся материал не дает нам права сравнивать по высоте открытые гласные с закрытыми, и наоборот. Поэтому получаем две "параллельных" шкалы — которые, однако не совсем параллельны: их внутреннее строение различно: тон—тон—полутон—тон для открытых гласных, тон—полутон—тон—тон для закрытых. Где-то мы это уже видели... Где? А вот здесь:
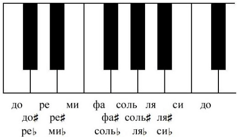
Мы снова в музыкальном классе, и можно задавать все те же странные вопросы... Только с ответами теперь намного интереснее. Потому что про внутреннее устройство и логику исторического развития звукорядов мы уже многое знаем...
Начать можно с прямого сопоставления наших фонологических структур и клавиатуры фортепиано:
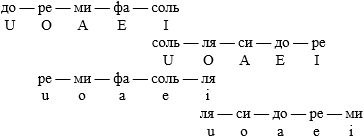
С одной стороны, становится понятно, откуда растут ноги у традиционной фонологии. Классическая диатоника, фундамент европейского музыкального мышления на протяжении пары тысячелетий. Вполне ожидаемо, что в эпоху господства "хорошо темперированного" строя фонологическое сознание не отстает, и встраивает в диатонику альтерированные ступени (кластеры), в полном соответствии с нормами 12-тонового звукоряда. Однако изначально ожидалось нечто вроде полного набора ступеней в пределах октавы — а вместо этого несколько пересекающихся квинтовых диапазонов, и особой роли октавы (как в музыке) совершенно не просматривается...
По зрелом размышлении начинаешь думать: может быть, это и правильно? Материал музыки и речи очень различен, и какие-то особенности в образовании фонологических шкал быть должны. Диапазон музыкальных звуков намного шире — и там октавные удвоения в порядке вещей. Речь гораздо "камернее", приземленнее; она по долгу службы должна быть доступна всем, а не горстке талантов. Выработать октавную масштабность в таких условиях — из области фантастики. Но и в музыке октава далеко не сразу стала осознанной нормой. Например, даже после того, как диатонические ладовые системы сложились в античной музыке, весь набор доступных тонов долгое время делили на тетрахорды (квартовые структуры), и заполняли октаву набором пересекающихся тетрахордов — в точности как у нас обстоит дело с фонемами (разбитыми, правда, на отрезки не из четырех, а из пяти ступеней, что по аналогии можно было бы назвать "пентахордами"; в теории музыки такой термин тоже встречается, в том же значении). Лад как последовательность семи нот в пределах октавы — это достижение средневековья, унаследованное последующими поколениями профессиональных музыкантов. При этом в народной музыке продолжали господствовать попевочные системы, и думал народ на масштабными конструкциями, а коллекциями типовыми блоков.
Известно, что в музыке чистая квинта — это своего рода переход от одного певческого регистра в другой; именно качеством квинт отличается хорошо поставленный голос от всяческой самодеятельности. Вполне логично, что квинта ограничивает диапазон гласных в языке: пока мы остаемся в пределах одного регистра, освоение фонологической системы не требует героических усилий от народных масс. Переход от открытого произношения к закрытому в этом контексте вполне аналогичен регистровым различиям музыкальных инструментов, для которых даже ноты записывают по разному, со сдвигом вверх или вниз (скрипичный ключ, басовый ключ, ключ "до" и т. п.). В практике игры на гитаре ту же роль играют специальные накладки на гриф, которые зажимают струны на определенном ладу — и тем самым меняют регистр инструмента, позволяя единообразно (не меняя аппликатур) исполнять музыку в разных тональностях.
Тут уместно вспомнить и о физиологии речи. Без всякого умысла, мы получили весьма примечательный факт: гласные упорядочены в точном соответствии со способом артикуляции. Действительно, эмпирическое наблюдение показывает, что русские гласные произносятся практически без участия языка, губами. В этом отличие русского языка от французского — где важно еще и положение (передние — задние), и носовой оттенок... Если теперь проследить за конфигурацией губ при движении вдоль полученной теоретической последовательности, мы видим плавную траекторию от полной огубленности, через нейтральное положение, к сильной растяжке. Такие совпадения случайными не бывают...
Поскольку мы (с учетом кластеров) обнаруживаем вполне сложившийся "звукоряд" из двенадцати тонов, логично допустить, что какие-то из свойств музыкальной шкалы проявят себя и в фонологии. Теория предсказывает, что всякая шкала имеет какие-то подструктуры, которые не случайны, а определяются культурой восприятия. В частности, для 12-тоновой системы возможные "вложения" могут состоять из семи (диатоника), пяти (пентатоника) или трех звуков (трезвучие). Впрочем, это мы знали и без вычислений: есть белые клавиши (ровно семь штук на октаву), черные клавиши (как раз пять) — и есть всевозможные "аккорды", задействующие как белые, так и черные клавиши. Как все это применить в науке о языке — тайна.
По части тональностей и пентатоники — можно поспрашивать поэтов. Сразу видно, что открытые гласные обрисовывают мажор, а закрытые — минор. Тогда всякая речевая интонация может опираться на характерную последовательность открытых и закрытых гласных, с намеком на один из хорошо изученных музыкальных ладов. Древние греки частенько прилаживали тетрахорды к инструментам, перенося (транспонируя) их вверх или вниз на несколько ступеней. Понятно, что в исходную настройку это уже не вписывалось — и звуки "полной и неизменной системы" приходилось менять, в соответствии со строением лада. Сразу вспоминаем про взаимную адаптацию фонем — и делаем выводы.
Старинная музыка (подобно речи) развертывалась главным образом во времени: мелодия превыше всего. Гармонический слух развивался очень постепенно, — и у широких масс он даже сейчас в зачаточном состоянии. Можно играть в угадывание мелодий — угадывать музыку по аккордам намного сложнее. При одновременном исполнении, меньше всего противоречат друг другу тона, отстоящие друг от друга на интервал октавы и квинты. Поначалу старались этим и ограничиваться. Для современного музыканта квинта — вообще не гармония, а сплошная пустота. Это пережиток тысячелетий, прожитых под знаком чистой квинты, тяжелой наследие Пифагора... Сейчас известны строи, в которых квинта звучит иначе: мягко и насыщенно. Такие квинты кое-где используют в народной музыке и на эстраде; классика пока от комментариев воздерживается.
Трезвучие соединяет интервалы квинты и терции. От этой просто операции в музыке все переменилось: битвы были нешуточные — и в конечном итоге "придумали" 12-тоновую систему как (почти) всех устроивший компромисс. Конечно, музыкальных гениев оно устроить никак не могло; они изначально относились к такой уравниловке скептически — и до сих пор изобретают что-то совсем не такое... Но мы люди простые — нам бы в русской фонологии как-нибудь.
В быту наша речь не балует многоголосием. Сначала один звук, потом другой. Чтобы реально заметить аккорд, надо изобрести другой речевой инструмент. Не то, чтобы это было совсем невозможно: компьютерный прогресс понемногу приучает нас к мультимедийности, и зачатки гештальтного восприятия текста (чтение "по диагонали") развиваются в способность распознавать скрытые структуры. Если еще искусственный интеллект подсобит — научимся. Вспомним, что в современной музыке композитор не обязан предъявлять аккорды в явном виде, в одновременном исполнении: достаточно наметить характерную последовательность нот, чтобы (достаточно грамотный) слушатель склеил их в восприятии и узнал притаившуюся в мелодии гармонию. Нечто похожее возможно и в речи. Если как следует покопаться в текстах (особенно художественных), набрать достаточное количество примеров — перспектива очень даже реальная. Но это тема для специального трактата. А пока вернемся к началу беседы, вспомним о таинстве случайных встреч.
Встречаются две гласные, и что-то между ними происходит — или не происходит. Что и когда? Почему-то мы иногда воспринимаем такие встречи как соединение — а в другой раз как противопоставление. Даже если нет в русском языке дифтонгов по паспорту, взаимная притирка и метрическое стяжение — безусловный факт. На полях ставим галочку: среди согласных такое бывает не реже; но дифтонгами это никто никогда не называет...
Дифтонги чем-то похожи на кластеры: и то, и другое воспринимается как объединение нескольких фонем. Однако, в отличие от втиснутых в мгновение кластеров, в дифтонгах такое соединение происходит внешним образом, как заметное движение внутри целого (ср. слоги китайского языка: целая поэма в одном иероглифе). Но: движение именно внутри! Стоит акцентировать различия — и дифтонг распадается на последовательность гласных.
С точки зрения математической теории шкал, речь идет о настройке человеческого (то есть, культурно обусловленного) восприятия на различение деталей определенного масштаба: когда различия не выходят за пределы допустимого — это целостное образование, дифтонг. Поскольку у нас имеется приблизительное сопоставление гласных русского языка ступеням музыкального строя, можно попробовать выписать нотные аналоги сочетаний гласных в речи:
| [(A)i] |
таинственный |
си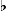 — ля — ля |
| [U(i)] |
дует |
соль — ля |
| [O(i)] |
свой |
ля — соль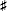 |
| [(A)i] |
свои |
си — ля |
| [i(i)] |
синий |
ля — соль |
| [e(i)] |
теплей |
соль — ля |
| [(u)A] |
нюанс |
ля — си |
| [(i)O] |
белье |
соль — ля |
| [(A)i] |
строитель |
си — ля |
| [O(i)] |
воин |
ля — соль |
| [(i)O] |
неон |
соль — ля |
| [(A)i] |
наивный |
си — ля |
| [e(i)] |
клеить |
соль — ля |
| [(A)e] |
настроение |
си — соль / ми — соль |
| [(A)(i)] |
боевой |
си — ляc |
| [(A)(i)] |
наибольший |
си — ля |
Для сравнения:
| [(U)A] |
тротуар, дуальный |
до — ми |
| [(i)(A)] |
леопард, неофит |
соль — ля / ми — cи |
| [(A)E] |
поэтический, маэстро |
ре — фа |
Что можно отсюда усмотреть? Простую вещь: когда мы воспринимаем соседние гласные как почти сливающиеся, музыкальный интервал между ними составляет только одну ступень — это ближайшие соседи по фонологическому "звукоряду". В тональной музыке это называется вводным полутоном: один звук сильно "тяготеет" к другому и "разрешается" в него. Чуть больше — и мы слышим только последовательность гласных, без взаимных претензий. Понятно, почему мы норовим разрезать французский дифтонг [ua] на отдельные слоги: французы иначе упорядочивают гласные, и у них соседями могут оказаться звуки, для русского четко разделенные. Если мы захотим произнести по-французски, у нас получится нечто вроде [(O)A], соответствующее вводному полутону ре — ми.
Важный вывод: русский язык достаточно продвинут в фонологическом отношении и четко различает ступени 12-тоновой системы. Наличие вводного тона — характерная особенность этого строя. При менее детализированном восприятии возникают другие шкалы. Отсутствие дифтонгов в русском языке — следствие его фонологического строения: вводный полутон — это всегда мелодический ход, и потому на стыке гласных обязательно присутствует невидимый барьер, незаметное придыхание, которое в лингвистике называется "шва". Следовательно, русский слог всегда оказывается парой согласная + гласная, и других вариантов нет! Это весьма нетривиальный результат, к которому не все сразу привыкнут. Обсуждение сопутствующих обстоятельств — как-нибудь в другой раз.
Что остается? Тайна. Посмотрим еще одну табличку:
| [e(i)] |
сильней |
соль — ля |
| [eE] → [e(A)] |
сильнее |
соль — фа → соль — си |
| [A(i)] |
тайна |
ми — соль |
В первой строке мы видим вводный полутон — и чувствуем склейку соседних гласных, что кириллица незамедлительно отражает в графике. Попробуем теперь не редуцировать окончание (вторая строка таблицы). В реальности мы все равно заменим безударную гласную кластером — но это уже будет другая нота, далеко отстоящая от первой. То есть, сначала гласные у нас расползаются в восприятии — а потом начинают звучать как одна, удлиненная фонема! Музыка подсказывает: мы слышим малую терцию. Основу минорной гармонии. Остается только заметить, что в слове тайна отчетливо прослушивается большая терция; а вместе с (отделенной лишь носовым оттенком) последующей гласной [A] (из другого пентахорда) — полное мажорное трезвучие.
|



